
Well, so much for easy grouping. As opposed to before, when I saw my models clustered, there’s instead a smooth progression from the worst to the best. There is an interesting group of 4 at the bottom, so I’ll use a group of 5 at the top to balance them, and then split the remaining two groups roughly down the middle.
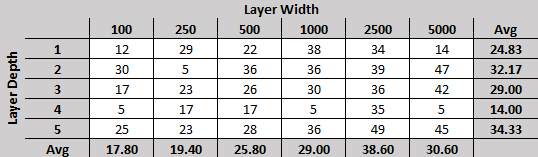
As a quick reminder, each round every network plays every other network twice, alternating who goes first, for a total of 58 games per contender. Ties are counted as losses for both sides, and the numbers presented above are the average number of games won for rounds 28, 29 and 30.
First, the groups:



What we see here is a steady progression from the wider networks to the narrower ones. I’m still surprised by the lack of correlation with model depth, but it is possible that model depth (allowing the equivalent of higher-order / more strategic thinking, or rather, patterns of patterns) does not demonstrate an advantage until a certain quality of play has been achieved. These models are all still rather simplistic in their pursuit of filling columns, and only in the last few rounds have they begun to recognize horizontal threats.
Quick note: I am aware that using convolutional networks would help tremendously, and I plan on making use of them in the next stage of my experiment; for now though, I wanted to observe networks that varied purely in width and depth.
Now, for the 4x networks… I must say, they are very disappointing. They seem to be stuck in a rut for some reason and are unable to pull out. In fact, each of them has been at this level of performance for several rounds now (the most recent addition is the 4×100 which dropped to this level in round 25). However, there is still hope for them: the 5×100 network was at a similar level of performance from round 7 until round 20 and is now at a respectable 3-game-average of 25 wins per round.
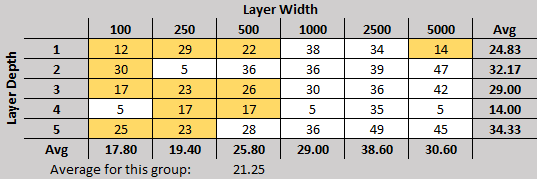
What’s nice about the current set of data is how the results are finally grouping themselves into something I can see a pattern in. For instance, check out the group I previously called consistently good in my previous post, and compare them to the tiers shown above:

They’re really grouping much better now, with a steady progression in quality as the layers get wider.
Another change from last time is the performance of the most complex network, five layers deep and 5000 nodes wide. Here’s what I wrote before:
Before the start of this little experiment, I would have expected the largest, most complex models to perform best. While the 5×5000 model consistently wins over half its games it is much more variable than the more consistent group examined above. The 5×5000, in fact, ranges in wins from 28-41, with its most recent 3-game-average at 36.
When looking at the final 3-game-average for the top models makes it look like the 5×5000 is trailing 5×2500 and 2×5000, all 3 won 49 games in the 30th round. As always, more data will show us if it has seriously improved or if that was a fluke.
Finally, I’ve been testing the models against a purely random player, followed by testing them against a basic expert system (the Smart Random player) to determine which networks to use for generating the following set of training data. I posit, but don’t actually know, that performance against the one strongly correlates with performance in the Round Robin Tournament.
So I plotted the number of games won in the tournament (horizontal, out of 38) with the number of games won against the SRP (vertical, out of 1,000) for rounds 20-30.
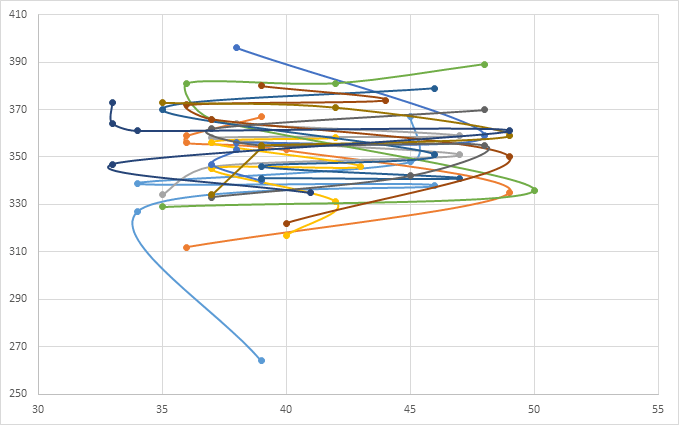
That’s not much of a correlation.
Maybe there’s simply too much data? Here’s the chart with only rounds 26-30:

Unfortunately, this is just as bad.
I’m going to keep testing against the SRP every round just so I can track the results, but the models used to generate training data will be chosen purely based on the round robin tournament for the next set of rounds.
