
OK, I haven’t been running as many training rounds as I should, in fact, I’d only managed a half dozen between the Great Training Data Fiasco of March 1st and the graphical/multithreaded rewrite I finished at the end of April. At that point, the effectiveness of my model networks still hadn’t recovered, and some of them were still so bad that I may as well have been starting from scratch.
Partly I’d been having stability problems with the computer itself. My laptop was fine but too slow for heavy-duty training, so I was using the HTPC I’d built with an NVidia 1060 card, but the shell was an AMD Phenom X2 that I’d bought off Craigslist. I replaced it with an Intel Pentium G4620 (2 Kaby Lake cores, 4 threads, 3.7GHz) with 16GB of DDR4 and a SanDisk 500GB SSD. It’s fast, it’s silent, and it also plays games on the TV at a solid 60Hz (that’s the other reason I haven’t been doing as much on this as I should: I’ve been revisiting The Witcher 3).
Anyway, I restarted my round numbering on the new computer, because I made several changes to my methodology at that time.
Previously, my learning rate had fixed values and was decreased by fixed amounts at set intervals. Now, it’s adaptive. I start it as large as I can without running into exploding gradients, then decrease it by a percentage whenever it is no longer learning effectively.
I also experimented some with the number of training epochs, testing between 10 and 40 before generating a new set of training data. With the automatically adjusted learning rate, it seems that the sweet spot (capturing most of the benefits in as short a time as possible) seems to be 15-25 epochs. Obviously, this would be different if I had higher quality training data, but since I’m just throwing it away every round and generating a new set I’m not too worried about it. So, to save time, I have it currently set to 15.
How I generate the training data also changed. The top 12 models from the round robin tournament are tested against a purely random play, followed by testing the top 6 against the Smart Random player, with the top 3 being used to generate training data. As I wrote previously, I was playing games until I had a fixed number of moves generated, and just using all the games played as the data set. Now, I’m looking at an equal number of wins and losses by each player, playing both as red and black, and going for a total number of games. In other words, if I have 3 players, and I want a total of 3,000 games, then each player will need to generate 1,000 games. Further, those will be split up into 250 wins as red, 250 wins as black, 250 losses as red and 250 losses as black.
Finally, I’ve experimented with the size of the training set. While I was previously looking at a total number of moves, now I’m looking at a total number of games. Since most games averaged 16 moves before, that would be 8 moves by the winner added to the training set per game (I haven’t checked average game length in a while, that could have changed). So to generate my 100,000 moves would require approximately 12,000 games (plus or minus). For my new method, I’ve tried using somewhere between 100,000 and 250,000 games. I’ve settled in on 100,000 being “good enough for now,” but will definitely increase this once they stop progressing.
Partly these changes were motivated by increasing the effectiveness of my method but partly also by time constraints. I find a period of about 6 hours seems good for training, which is what it takes me to run 15 epochs against a training set of 100,000 games. If I were only training a single model, instead of 30, then I’d increase both the number of training epochs and the size of the data set, but for now, this works.
Anyway, what’s really interesting is what has happened over the course of the last dozen rounds as my models have worked with the new methods. The models have quite clearly separated into 2 groups with outliers.
First, the raw results. This is the average number of games won (out of 58) over the final 3 rounds of training:
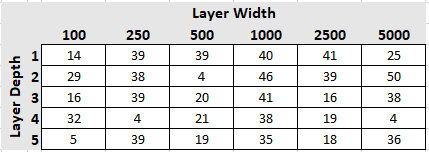
The first group that I’d call your attention to is consistently good. They all win between 38 and 41 rounds and don’t stray much from that range. Their individual standings mary shuffle around a bit, but mostly this group stays together.
Surprisingly we see a representation of relatively simple models here, either of the single-layer variety or of the not-very-wide type (the x250s). Other than that, there is no pattern. Perhaps we can infer that a simplistic network is simply better at picking up patterns? We’ll see what happens over the course of the next few dozen rounds.
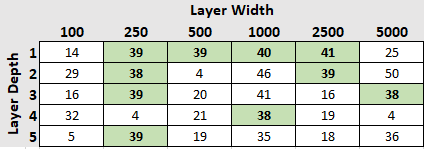
The next group is really a group of stragglers. Their standings within the tournament vary wildly, one round doing much better and another round doing much worse. Their 3 game averages range from 14 to 36 games won.
No surprise from the 100-node-wide models here; with 84 input signals, and a dropout rate of 50%, that means each epoch you train 50 nodes to discern a pattern from 84 signals. Possible, but difficult.
What’s surprising to me is the over-representation of the 5-layer-deep networks. Before the start of this little experiment, I would have expected the largest, most complex models to perform best. While the 5×5000 model consistently wins over half its games it is much more variable than the more consistent group examined above. The 5×5000, in fact, ranges in wins from 28-41, with its most recent 3-game-average at 36.
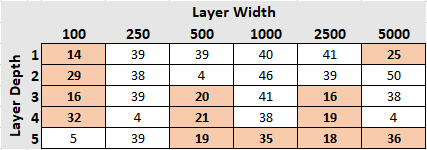
Now for the outliers. At the bottom of the pack we have a set of 4 models that have gotten stuck in a rut and, over the past half-dozen games have performed abysmally.

And, on the other end of the spectrum, we have the clear winners.
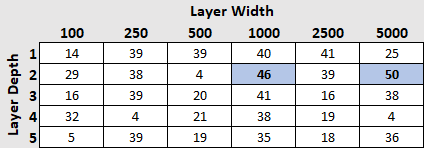
These two models started out in the middle of the pack but have clearly separated themselves from the group, improving their performance after every round.
We’re only 13 rounds into the new era of large data-sets and adaptive learning rates, so it’s impossible to say if these results will hold true in the future. I’ve already seen rapid changes in the performance of the models against the SRP though, so I’m excited to see what other changes we’ll see in the future.
As for playing against me, the games aren’t very interesting. We’re still seeing an obsessive focus on filling columns vertically with no other strategy. After a few more rounds I’ll evaluate them again and see if they’ve picked up any new tricks.
