
So I ran a few dozen more rounds, and the models pretty much stopped learning. The best of them would win around 80% of their games against the expert system (SRP).
Here’s how each model performed against the SRP (5,000 as black, 5,000 as red, for a total of 10,000 games each):
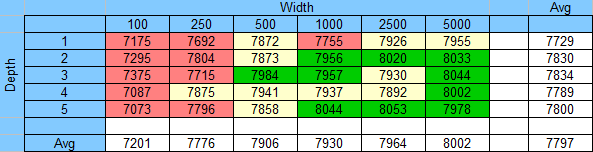
The results are split into the top, middle, and bottoms thirds for easy comparison.
As in previous rounds, there’s no correlation between depth and performance (except for the single layer network). There is a definite advantage to having a wider network, but that advantage diminishes after going 1,000 wide.
This is what I’ve seen in pretty much every set of results, so I think it’s fairly solid. I’m going to stop running the whole set and, instead, focus on training a single Neural Network to beat me.
The new network, nicknamed Larry, started off with two convolutional layers, followed by a normalization layer and then a wide fully connected layer.
I set the computer to train him for 25 epochs, then generate a new set of training data, then train again. As before, the training data is comprised 50% of wins and 50% of losses against the SRP. I started with a set of training data provided by the best of the networks above, and after the first set of training, Larry performed with a comparable 80% win rate. I then set the computer to loop the above and went to bed.
When I woke up, Larry’s win rate had dropped to 5%. Oops.
I then tried removing the normalization layer, so it was just the two convolutional layers and the wide layer. I started over from scratch and, over night, Larry pulled his win rate from essentially 0 (brand new network and no training data) to >70%. Not bad.
That normalization layer is supposed to make it easier to use large learning rates, but obviously, it was detrimental here. It could be that the model is too simplistic; perhaps if I went 10 layers deep it would be useful, but it doesn’t do any good with only 3 layers.
I left it running when I went to work this morning, so I’m interested in seeing how well it’s done when I get home. Also, it’s time to look into more expert systems for playing Connect4, to see if I can get him better training data. The SRP isn’t going to cut it anymore.
