
First off, playing the winner. I was pleased that the AI not only pursued its own win, but was smart enough to block my play in column 3. However, it failed to block my second play in row 0. Still, a definite improvement!
Now, the round robin: There was, again, a HUGE amount of variability here. In fact, more than the initial set of 5 rounds.
I took the number of games each AI won every round, calculated the Standard Deviation for each of them, and found that they all increased. An AI that would do well one round would do poorly the next. There is simply to rhyme nor reason to who wins each round.
I did, however, detect a clear pattern when I looked at games won over the five rounds, grouped by layer size and width:
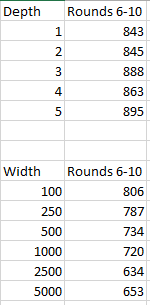
Again, we see a clear trend towards narrower networks, and a slight trend towards deeper ones.
I decided to kick-start the training a bit so, for the next set of rounds, I’m training each network for 100 epochs instead of 25. Happily, this still completes in a single overnight session, the first of which I finished this morning.
One thing I noticed, after training for 100 epochs, is that the smallest networks stop improving around the 25th epoch. The mid-range ones stopped improving around epoch 50, and only the largest were able to continue converging on the training data through the 100th epoch.
If I adjust the learning rate at certain epoch numbers, this will allow the smaller networks to continue learning (even if it is at a slowed pace). However, doing so would mean the larger networks have their learning slowed. Of course, I could set different learning rates for each network, but I’m trying to keep things roughly equal.
Since small progress is better than no progress, and the larger networks already have a theoretical advantage, I’m going to adjust the learning rate to allow the small networks to continue converging on the training data.
